各种常用ID生成器的对比,重点介绍一下NanoId
一.UUID
优点
使用UUID作为主键具有以下优点:
1.分布式ID
UUID值在表,数据库甚至在服务器上都是唯一的,允许您从不同数据库合并行或跨服务器分发数据库。
2.安全性
UUID值不会公开有关数据的信息,因此在URL中使用更安全。
3.通用性
可以在避免往返数据库服务器的任何地方生成UUID值。它也简化了应用程序中的逻辑。
缺点
除了优势之外,UUID值也存在一些缺点:
1.存储空间多
存储UUID值(16字节)比整数(4字节)或甚至大整数(8字节)占用更多的存储空间。
2.调试似乎更加困难
想象一下WHERE id ='9d6212cf-72fc-11e7-bdf0-f0def1e6646c'和WHERE id = 10哪个舒服一点?
3.性能问题
使用UUID值可能会导致性能问题,因为它们的大小和没有被排序。
二.雪花算法
Snowflake 雪花算法,由Twitter提出并开源,可在分布式环境下用于生成唯一ID的算法。该算法生成的是一个64位的ID。在同一个进程中,它首先是通过时间位保证不重复,如果时间相同则是通过序列位保证。同时由于时间位是单调递增的,且各个服务器如果大体做了时间同步,那么生成的主键在分布式环境可以认为是总体有序的,这就保证了对索引字段的插入的高效性。例如 MySQL 的 Innodb 存储引擎的主键。
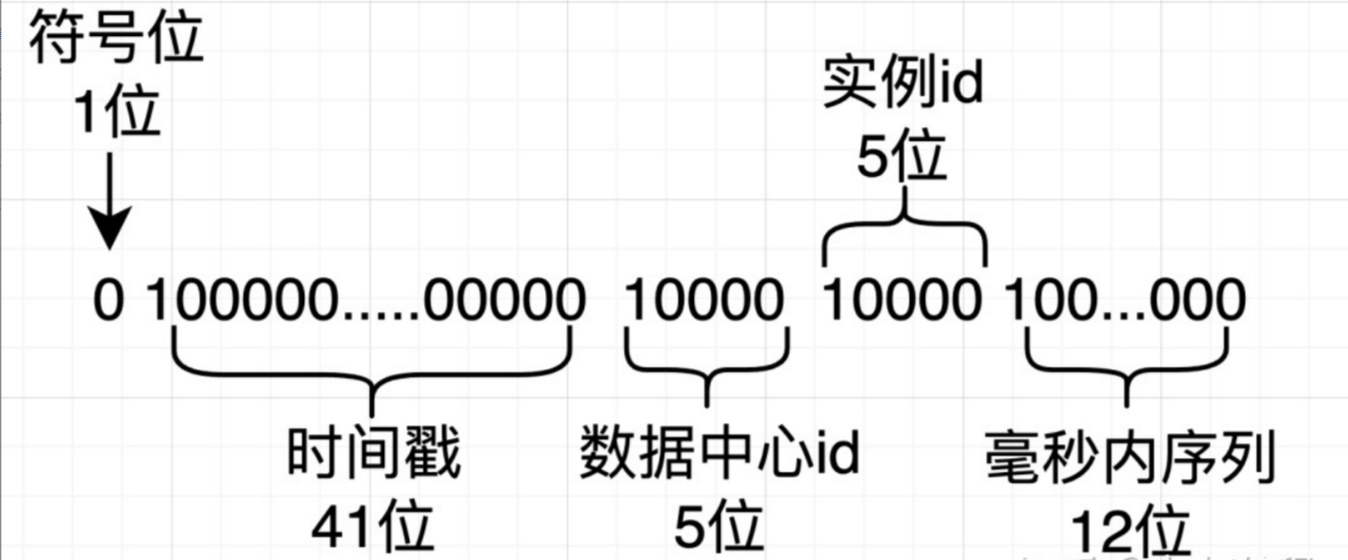
使用雪花算法生成的主键,二进制表示形式包含 4 部分,从高位到低位分表为:1bit 符号位、41bit 时间戳位、10bit 工作进程位以及 12bit 序列号位。
符号位(1bit) 预留的符号位,恒为零。
时间戳位(41bit) 41 位的时间戳可以容纳的毫秒数是 2 的 41 次幂,一年所使用的毫秒数是:365 * 24 * 60 * 60 * 1000。通过计算可知:Math.pow(2, 41) / (365 * 24 * 60 * 60 * 1000L); 结果约等于 69.73 年。Apache ShardingSphere 的雪花算法的时间纪元从 2016 年 11 月 1 日零点开 始,可以使用到 2086 年,相信能满足绝大部分系统的要求。
工作进程位(10bit) 5位workerId,5位datacenterId。 该标志在 Java 进程内是唯一的,如果是分布式应用部署应保证每个工作进程的 id 是不同的。该值默认为0,可通过属性设置。
序列号位(12bit) 该序列是用来在同一个毫秒内生成不同的 ID。如果在这个毫秒内生成的数量超过 4096 (2 的 12 次幂),那么生成器会等待到下个毫秒继续生成。
优点
1.整型且递增
为何追求递增?
因为递增最大的优势就是对磁盘IO是友好的。
熟悉磁盘结构的同学们都知道,随机写的效率是很慢的,
因为磁头需要转动到指定的位置,这个磁头转动的过程比起cpu或者内存来,完全不是一个数量级的,
所以如果能尽可能的使数据靠近在一一起(递增就能靠在一起),那么就不需要频繁的抬起磁头,转动磁盘,写数据了,一路写到底会快很多。
2.生成效率极高
在高并发,以及分布式环境下,除了生成不重复 id,每秒可生成百万个不重复 id,生成效率极高。
3.不依赖第三方库
不依赖第三方的库,或者中间件,算法简单,在内存中进行。
缺点
依赖服务器时间,服务器时钟回拨时可能会生成重复 id。
产生的id的组成:(符号位)+时间戳+机器id+序列号;
这三部分,机器id可以不重复,序列号也可以做到不重复,那唯一可能重复的就是时间戳了。
时间怎么会重复?
时间明明是一直向前的,除非时间倒退,退回到之前的某个时间点,再次产生的id才可能是重复的。
你说对了,人类感受的时间是不会倒退的,但是,机器上的时间都是时钟,时钟可能会因为种种原因变慢了或者变快了。
比如有一天你(或者机器上的时间同步器)发现有一台机器的时钟变快了,于是往回拨1秒,然后就可能会出现重复的id
消除时钟的问题
某些对时间及其敏感的程序,甚至会考虑使用GPS上的原子钟来做时钟同步;
或者,谷歌直接在数据中心自己搞原子钟,然并用处并不大,时间同步时的网络传输延迟、抖动,依然存在。
永远都是只能减小,无法消灭。三.NanoID
UUID 是软件开发中最常用的通用标识符之一。然而,在过去的几年里,其他的竞品挑战了它的存在。其中,NanoID 是 UUID 的主要竞争对手之一。但是,这两者之间的主要区别很简单。它归结为键所使用的字母表。由于 NanoID 使用比 UUID 更大的字母表,因此较短的 ID 可以用于与较长的 UUID 相同的目的。
优点
1.NanoID的大小只有108字节
与UUID不同,NanoID的大小比UUID小4.5倍,并且没有任何依赖性。这直接影响数据的大小。例如,使用NanoID的对象对于数据传输和存储来说既小又紧凑。随着程序的增长,这些特点将变得显而易见。
2.更安全
在大多数随机生成器中,它们使用不安全的Math.random()。但是,NanoID使用更安全的crypto module和 Web Crypto API。此外,NanoID在ID生成器的实现过程中使用了自己的算法,称为uniform algorithm,而不是使用random % alphabet.
3.速度快,结构紧凑
NanoID比UUID快60%。在UUID的字母表里有36个字符,而NanoID只有21个字符。
4.更多语言
NanoID 支持 14 种不同的编程语言,它们分别是:C#、C++、Clojure 和 ClojureScript、Crystal、Dart & Flutter、Deno、Go、Elixir、Haskell、Janet、Java、Nim、Perl、PHP、带字典的 Python、Ruby、Rust、Swift。
5.自定义字母,和长度
NanoID 的另一个现有功能是它允许开发人员使用自定义字母表。我们可以更改文字或 id 的大小
/**
* The default alphabet used by this class.
* Creates url-friendly NanoId Strings using 64 unique symbols.
*/
public static final char[] DEFAULT_ALPHABET = "_-0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ".toCharArray();
/**
* The default size used by this class.
* Creates NanoId Strings with slightly more unique values than UUID v4.
*/
public static final int DEFAULT_SIZE = 21;6.没有第三方依赖
由于 NanoID 不依赖任何第三方依赖,随着时间的推移,它能够变得更加稳定自治。从长远来看,这有利于优化包的大小,并使其不太容易出现依赖项带来的问题。
缺点
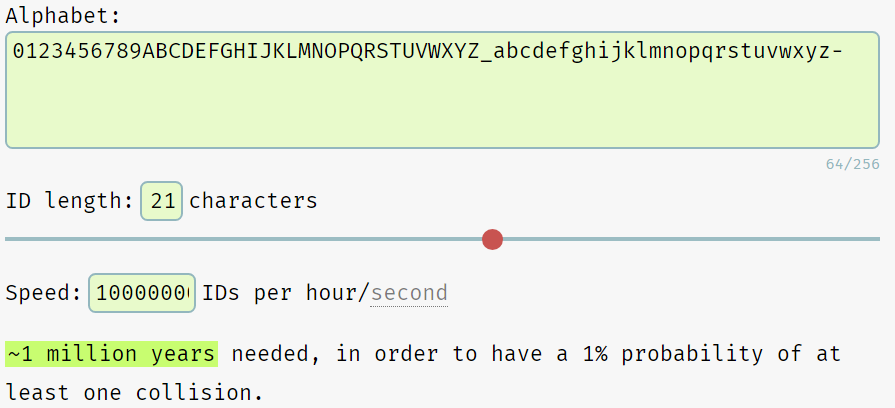
[Nano ID Collision Calculator] : https://zelark.github.io/nano-id-cc/
从官方给出的碰撞计算测试来看
每秒生成一亿个ID,100万年有1%的重复概率。比uuid还是差不少
四.mongoDB的ObjectId
ObjectID 长度为 12 字节,由几个 2-4 字节的链组成。每个链代表并指定文档身份的具体内容。以下的值构成了完整的 12 字节组合:
一个 4 字节的值,表示自 Unix 纪元以来的秒数
一个 3 字节的机器标识符
一个 2 字节的进程 ID
一个 3 字节的计数器,以随机值开始
